Learn the principles of tidy data to structure data in tables
Identify errors in existing data sets
Comments
Focus on only tidy data
Introduction of tidyr ways
tidyr provides functions to clean and tidy them but …
cleaning data also requires dplyr for most practical purposes.
A definition of tidy data
What are we talking about?
Variables: A quantity, quality, or property that you can measure.
Observations: A set of values that display the relationship between variables. To be an observation, values need to be measured under similar conditions, usually measured on the same observational unit at the same time.
Values: The state of a variable that you observe when you measure it.
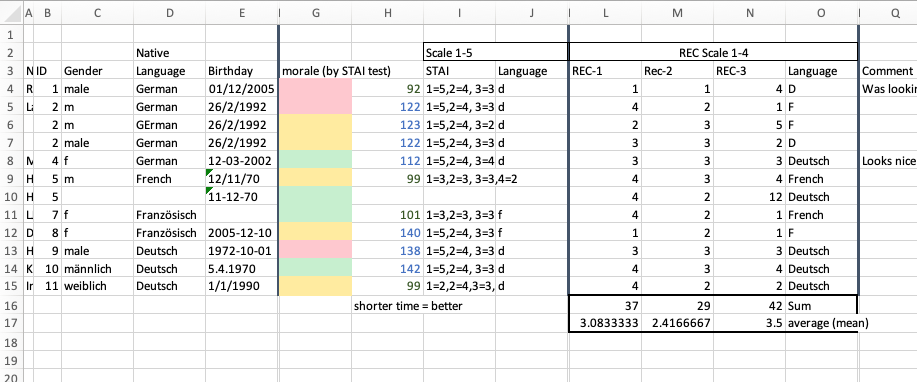
# A tibble: 12 × 20
rowid id gender language_4 test reaction `test-time` `rec-lang` rec_1
<int> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl>
1 1 1 m German dog 3 92 d 1
2 2 2 m German cat 3 122 d 4
3 3 2 m GErman cat 3 123 d 2
4 4 2 m German cat 3 122 d 3
5 5 4 f German dog 2 112 d 3
6 6 5 m French trolley 2 99 <NA> 4
7 7 5 <NA> <NA> <NA> <NA> NA <NA> 4
8 8 7 f Französisch trolley 2 101 f 4
9 9 8 f Französisch trolley 1 140 f 1
10 10 9 m Deutsch dog 1 138 d 3
11 11 10 m Deutsch dog 3 142 d 4
12 12 11 w Deutsch dog 5 99 d 4
# ℹ 11 more variables: rec_2 <dbl>, rec_3 <dbl>, language_16 <chr>,
# language_native <chr>, stai_1 <int>, stai_2 <int>, stai_3 <int>,
# stai_6 <int>, stai_5 <int>, stai_4 <int>, `NA` <int>
The tidyr package functionality
Common tidy data violations
Multiple variables stored in one column (e.g tidyr::separate_* functions)
Column headers are values, not variable names (tidyr::pivot_* functions)
Variables are stored in both rows and columns (tidyr::pivot_* functions)
Repeated observations (nest or separate tables)
Inconsistent data from manual entry (stringr, dplyr)
Multiple types in one table (dplyr, data transformation)
Tidy data solutions
Reshapes tables to become longer or wider , either adding rows or columns respectively
Basic column-wise manipulation (separate)
now after stringr
Reshaping operations (pivot)
after dplyr
Nesting and advanced collapsing operations (nesting)
after broom
tidyr 1.3.1
Major update of tidyr for column shaping in recent 1.3.0.
Functions separate() and extract() are superseded by more specific functions.
These older functions will be deprecated in 2024 .