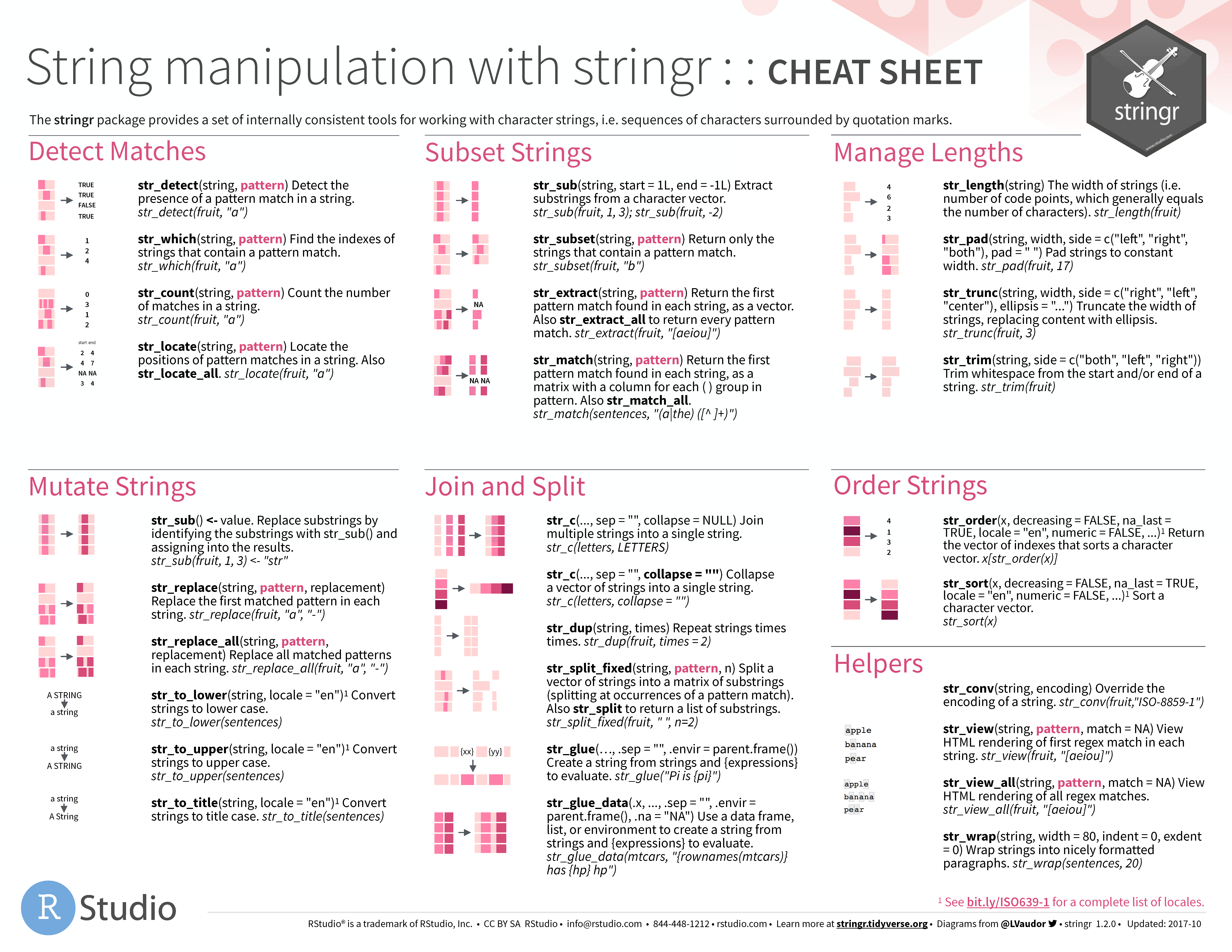
# A character object = colloquially called "string"
my_string <- "cat"
my_string[1] "cat"my_other_string <- 'catastrophe' # single quotes
not_so_numeric <- as.character(3.1415)
not_so_numeric[1] "3.1415"# A character vector
my_string_vec <- c("atg", "ttg", "tga")